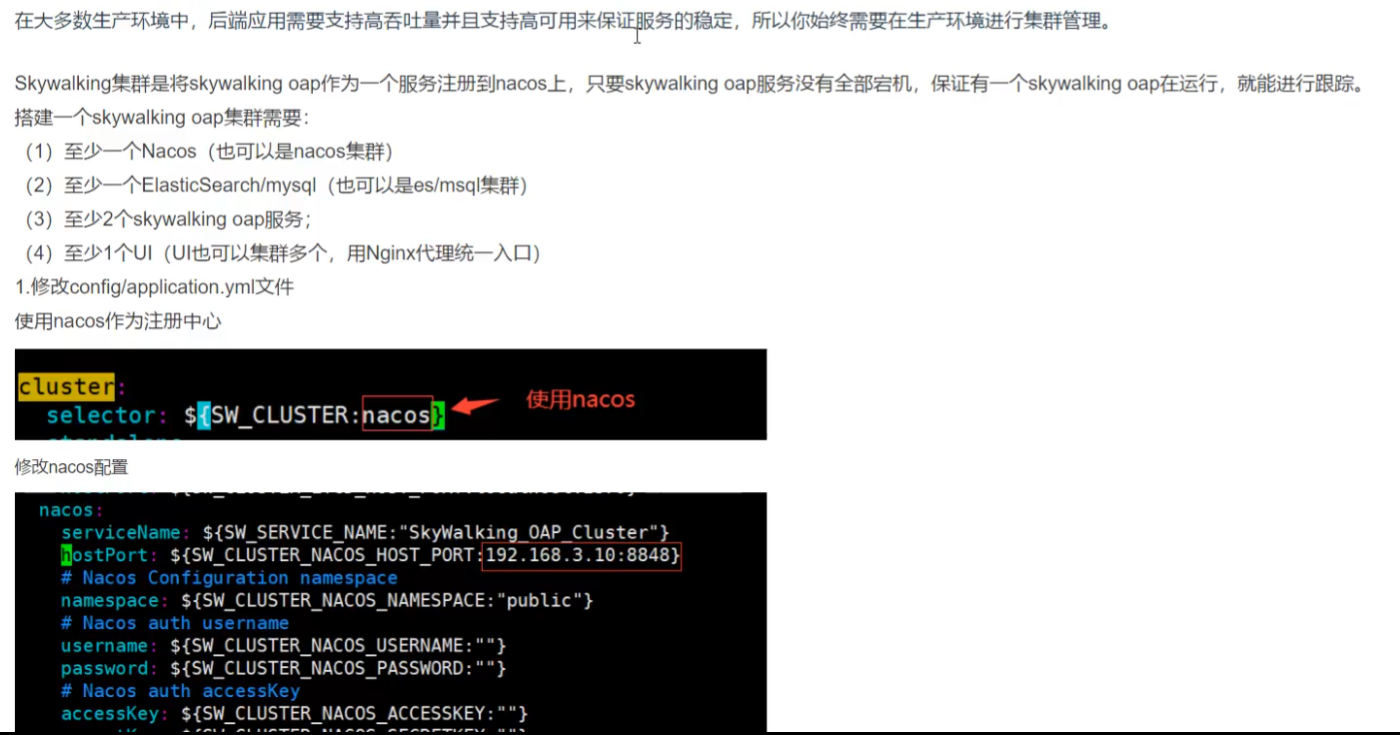
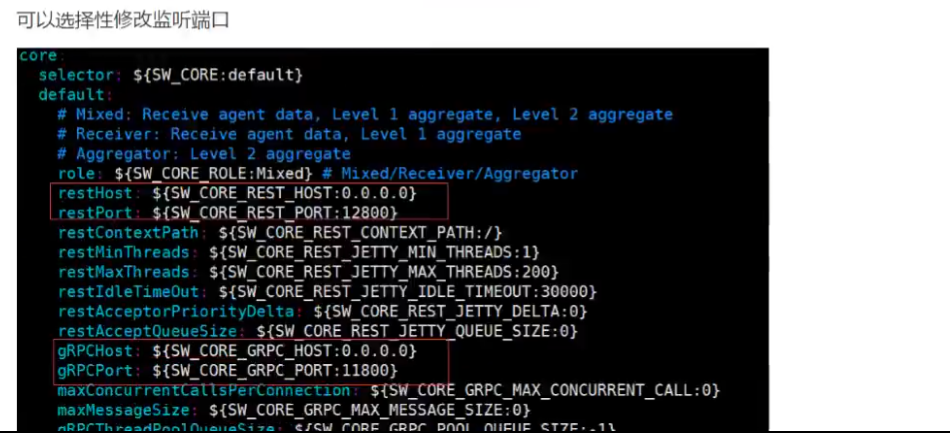
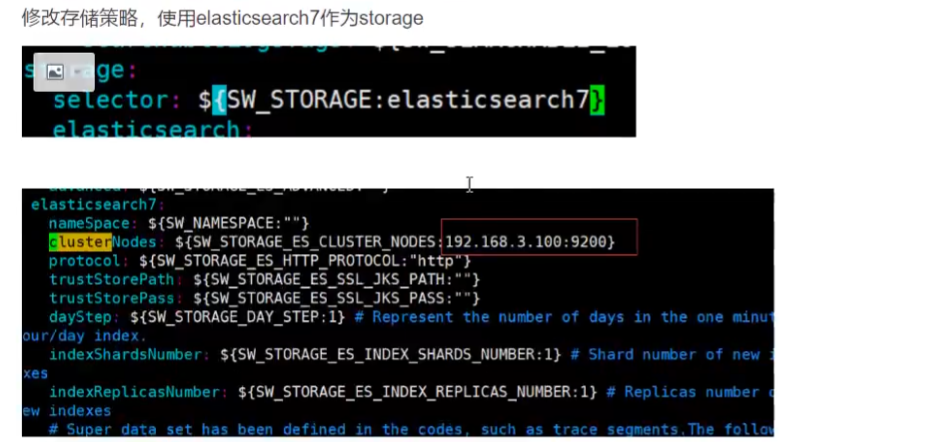
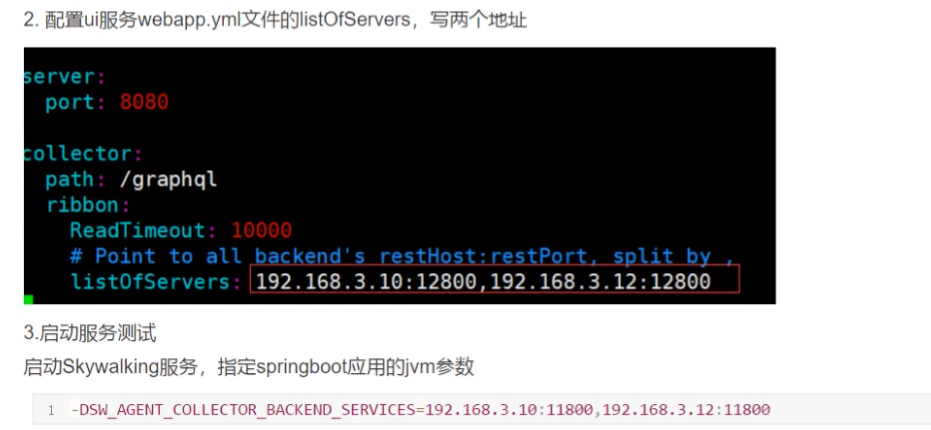
『 星火燎原 』
『 星火燎原 』spring-cloud-alibaba-demo
九、链路追踪
Sleuth链路追踪系统
- 分布式应用架构虽然满足了应用横向扩展的需求,但是运维和诊断的过程变得越来越复杂,例如会遇到接口诊断困难、应用性能诊断复杂、架构分析复杂等难题,传统的监控工具并无法满足,分布式链路系统由此诞生
- 核心:将一次请求分布式调用,使用GPS定位串起来,记录每个调用的耗时、性能等日志,并通过可视化工具展示出来
Sleuth和zipking(内部使用的鹰眼)
<!--链路追踪-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
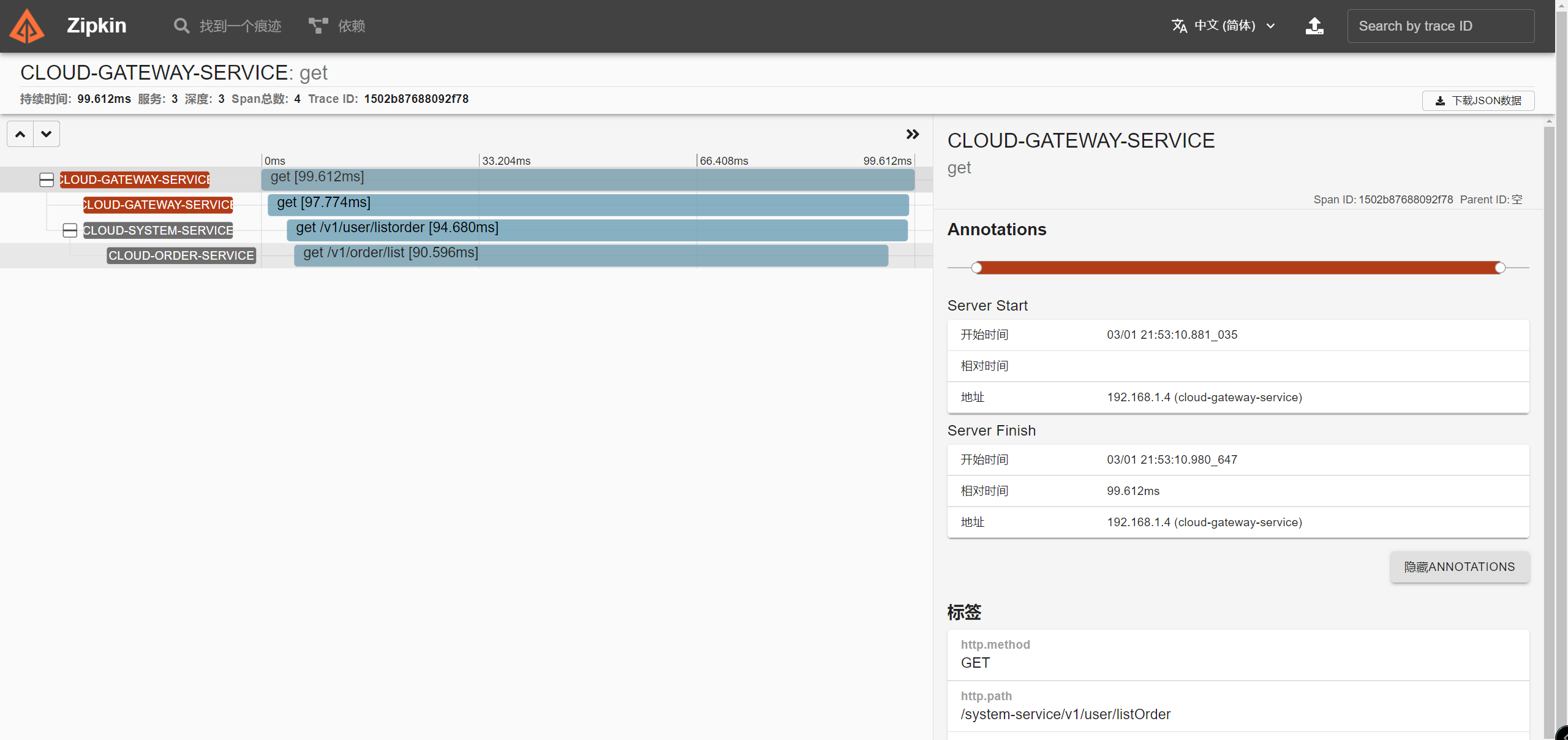
</dependency>调用网关【gateway-service】转发到【system-service】再到【order-service】
localhost:8002/system-service/v1/user/listOrder



第一个值,spring.application.name的值
第二个值,0faa27ad8177e6be,sleuth生成的一个ID,叫【Trace ID】,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
第三个值,852ef4cfcdecabf3、【spanid】基本的工作单元,获取元数据,如发送一个http
第四个值:false,是否要将该信息输出到【zipkin 可视化 服务中来收集和展示】。zipkin可视化 收集链路追踪信息
- sleuth收集跟踪信息通过http请求发送给zipkin server
- zipkin server进行跟踪信息的存储以及提供Rest API即可
- Zipkin UI调用其API接口进行数据展示默认存储是内存,可也用mysql 或者elasticsearch等存储
- 官网
- https://zipkin.io/
- https://zipkin.io/pages/quickstart.html
- 大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
- 同类产品
- 鹰眼(EagleEye)
- CAT
- twitter开源zipkin,结合sleuth
- Pinpoint,运用JavaAgent字节码增强技术
docker run -d -p 9411:9411 openzipkin/zipkin:2.23.0<!--收集链路信息-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>配置
spring:
zipkin:
base-url: http://127.0.0.1:9411/ #zipkin地址
discovery-client-enabled: false #不用开启服务发现
sleuth:
sampler:
probability: 1.0 #采样百分比默认为0.1,即10%,这里配置1,是记录全部的sleuth信息,是为了收集到更多的数据(仅供测试用)。
在分布式系统中,过于频繁的采样会影响系统性能,所以这里配置需要采用一个合适的值。

zipkin数据持久化
- 服务重启会导致链路追踪系统数据丢失,数据是存储在内存中的
- 持久化配置:mysql或者elasticsearch
- 创建数据库表SQL脚本
- 启动命令
方式一:持久化到mysql数据库
java -jar zipkin-server-2.12.9-exec.jar \
--STORAGE_TYPE=mysql \
--MYSQL_HOST=127.0.0.1 \
--MYSQL_TCP_PORT=3306 \
--MYSQL_DB=zipkin_log \
--MYSQL_USER=root \
--MYSQL_PASS=root数据库脚本
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);方式二:持久化到elasticsearch
java -jar zipkin-server-2.12.9-exec.jar \
--STORAGE_TYPE=elasticsearch \
--ES-HOST=localhost:9200注:测试发现使用最新版的elasticsearch-7.9.1,会有以下异常
java.lang.IllegalStateException: response for update-template failed: {"error":{"root_cause":[{"type":"invalid_index_template_exception","reason":"index_template [zipkin:span_template]invalid, cause [Validation Failed: 1: index_pattern [zipkin:span-*] must not contain a ':';]"}],"type":"invalid_index_template_exception","reason":"index_template [zipkin:span_template] invalid, cause [Validation Failed: 1: index_pattern [zipkin:span-*] must not contain a ':';]"},"status":400}解决方案:降低elasticsearch版本,使用elasticsearch-6.8.4数据可以正常持久化。
十、配置中心Nacos
- 现在微服务存在的问题
- 配置文件增多,不好维护
- 修改配置文件需要重新发布
- 统一管理配置, 快速切换各个环境的配置
- 相关产品:
- 百度的disconf 地址:https://github.com/knightliao/disconf
- 阿里的diamand 地址:https://github.com/takeseem/diamond
- springcloud的configs-server: 地址:http://cloud.spring.io/spring-cloud-config/
- 阿里的Nacos:既可以当服务治理,又可以当配置中心,Nacos = Eureka + Config
- 官方文档
添加依赖:
<!--配置中心-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
注意配置文件优先级
- 不能使用原先的application.yml, 需要使用bootstrap.yml作为配置文件
- 配置读取优先级 bootstrap.yml > application.yml
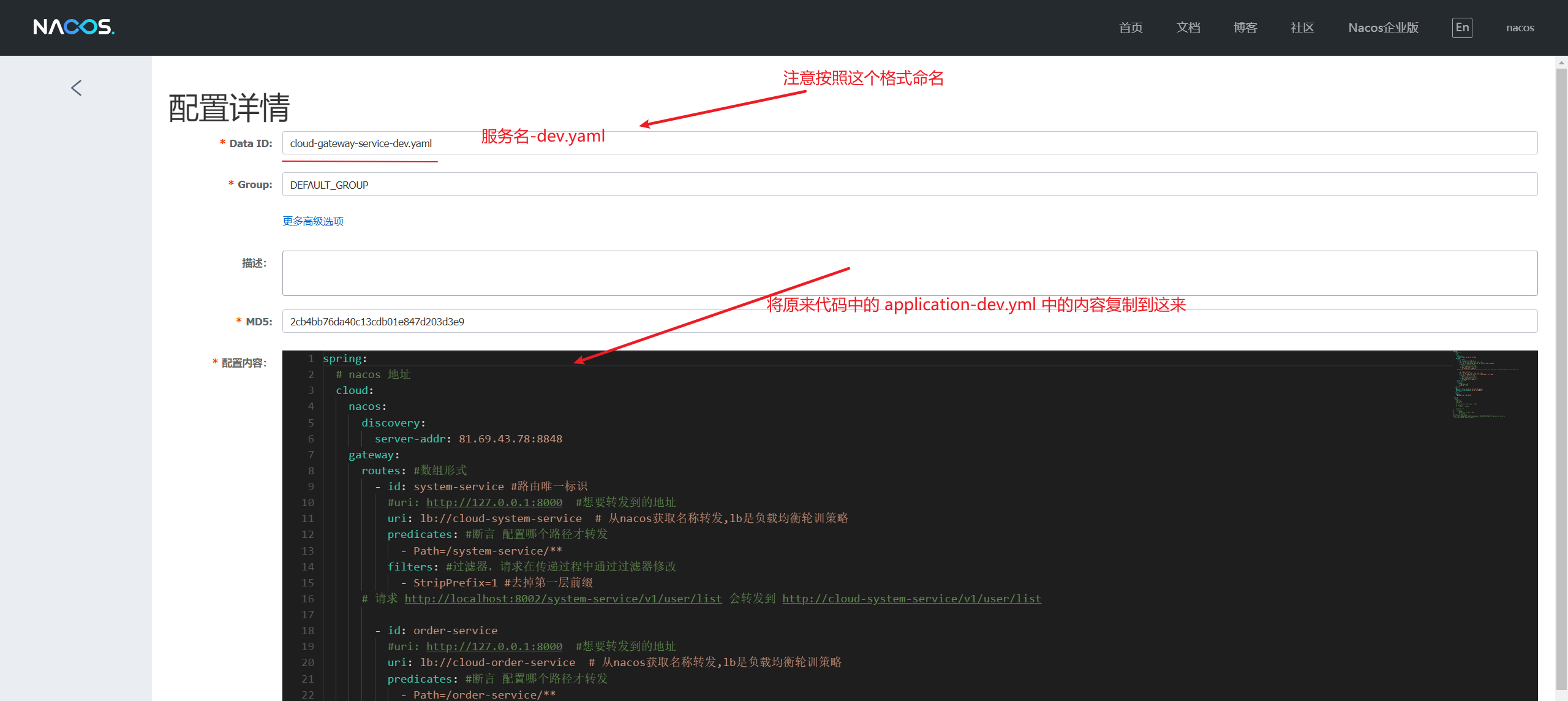
以网关服务(cloud-gateway-service)为例:
bootstrap.yml
spring:
profiles:
# 使用 dev 分支配置
active: dev
application:
# 应用名称
name: cloud-gateway-service
cloud:
nacos:
config:
server-addr: 81.69.43.78:8848 #Nacos配置中心地址
file-extension: yaml #文件拓展格式
server:
port: 8002将原来application.yml 注释,将原来application-dev.yml 拷贝到nacos中,将原来代码中的application-dev.yml注释

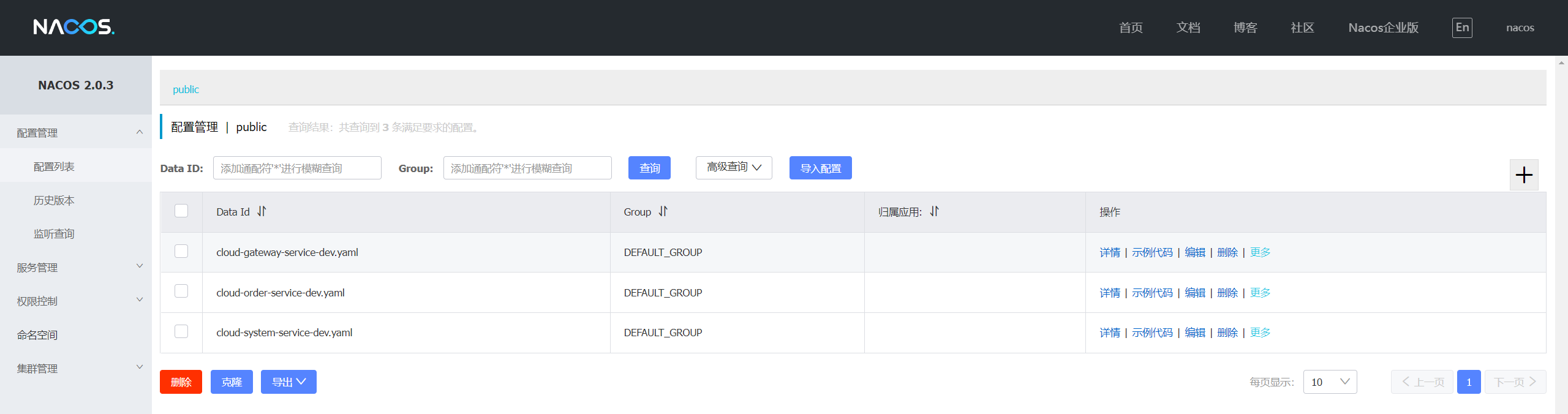
nacos中导出的配置文件:
nacos_config_export_20220301224344.zip
nacos动态刷新配置:
我们修改了配置,程序不能自动更新,动态刷新就可以解决这个问题
@RefreshScope 动态刷新
在nacos中配置 useLocalCache 的值,然后再代码中动态获取
@RestController
@RequestMapping("/config")
@RefreshScope
public class ConfigController {
@Value("${useLocalCache:false}")
private boolean useLocalCache;
@RequestMapping("/get")
public boolean get() {
return useLocalCache;
}
}十一、hystrix熔断降级(停止更新维护)
- 使用命令模式将所有对外部服务(或依赖关系)的调用包装再HystrixCommand或HystrixObservableCommand对象中,并将该对象放在单独的线程中执行。
- 每个依赖都维护一个线程池(或信号量),线程池被耗尽则拒绝请求(而不是让请求排队)。
- 记录请求成功,失败,超时和线程拒绝。
- 服务错误百分比超过阀值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。
- 请求失败,被拒绝,超时或熔断时执行降级逻辑。
近实时地讲课指标和配置的修改。
引入jar包
<!-- 整合hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>@EnableHystrix //在启动类上添加@EnableHystrix注解开启Hystrix的熔断器功能。

配置开启 feign对hystirx的支持:
feign:
hystrix:
# feign熔断器开关
enabled: true方法一:单独设置接口服务降级
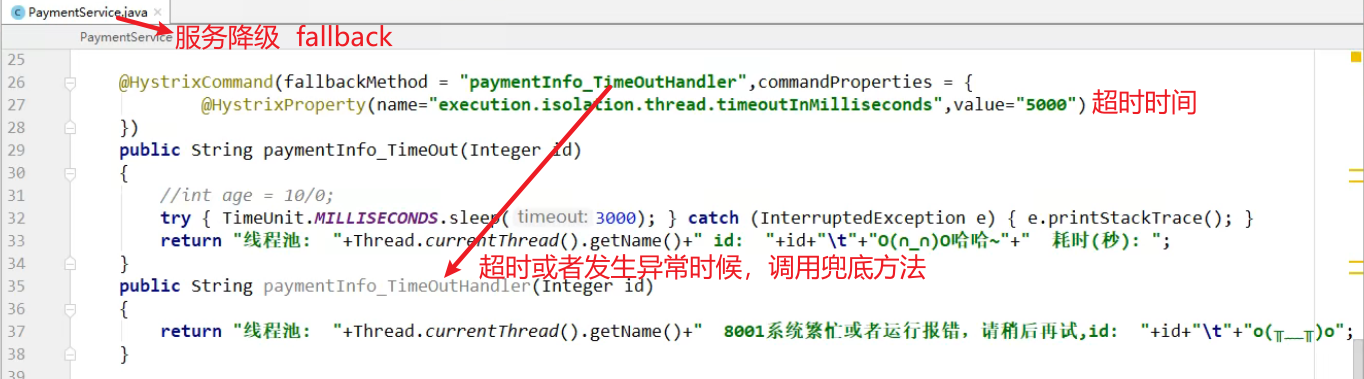
方法二:统一设置接口服务降级(推荐)
OrderFeignClient 客户端
/**
* @author zb
* @Description
*
* 服务降级-》进而熔断-》恢复调用链路
* 服务降级 fallback
*/
@FeignClient(value = "cloud-order-service",fallback = OrderFeignClientFallback.class)
public interface OrderFeignClient {
/**
* 获取订单列表
* @return
*/
@GetMapping("/v1/order/list")
R listOrder();
}OrderFeignClientFallback兜底类
/**
* @author zb
* @Description
*/
@Component
public class OrderFeignClientFallback implements OrderFeignClient {
@Override
public R listOrder() {
// 请求另外服务出错就会进入到这里的兜底方法
return R.fail("获取数据失败了,这是兜底数据哦。。。");
}
}设置服务熔断(顺序:服务降级—> 服务熔断 —> 恢复调用链路)
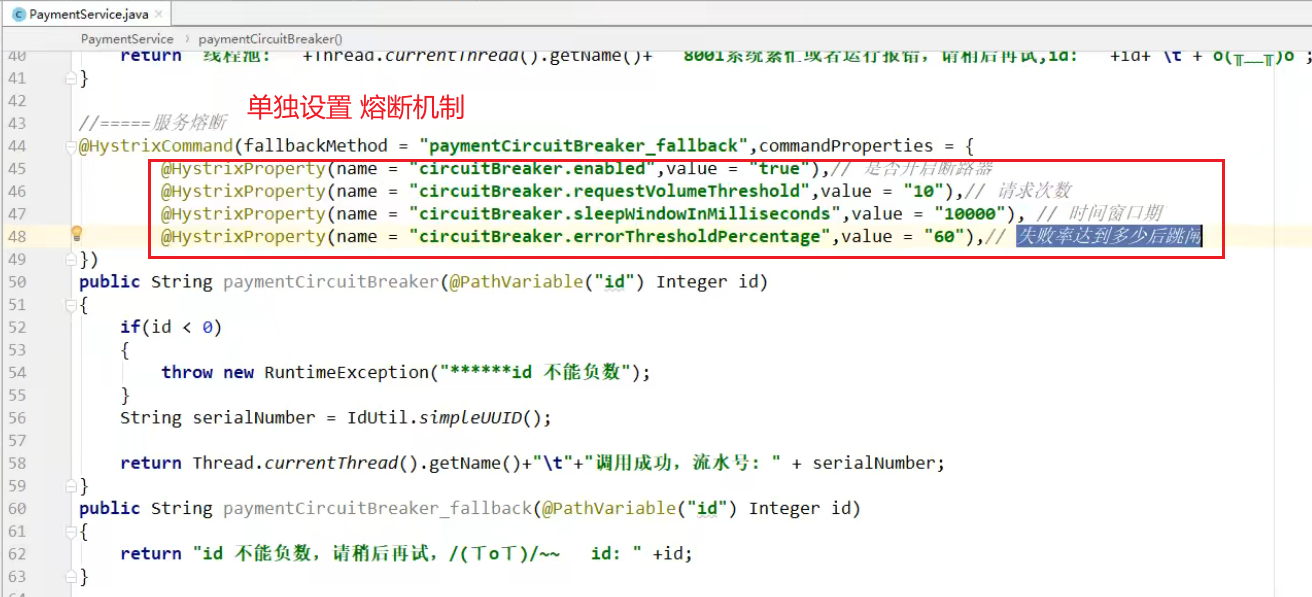
开启熔断器,在10s内10次请求里面有6次失败的话
配置参数配置出处
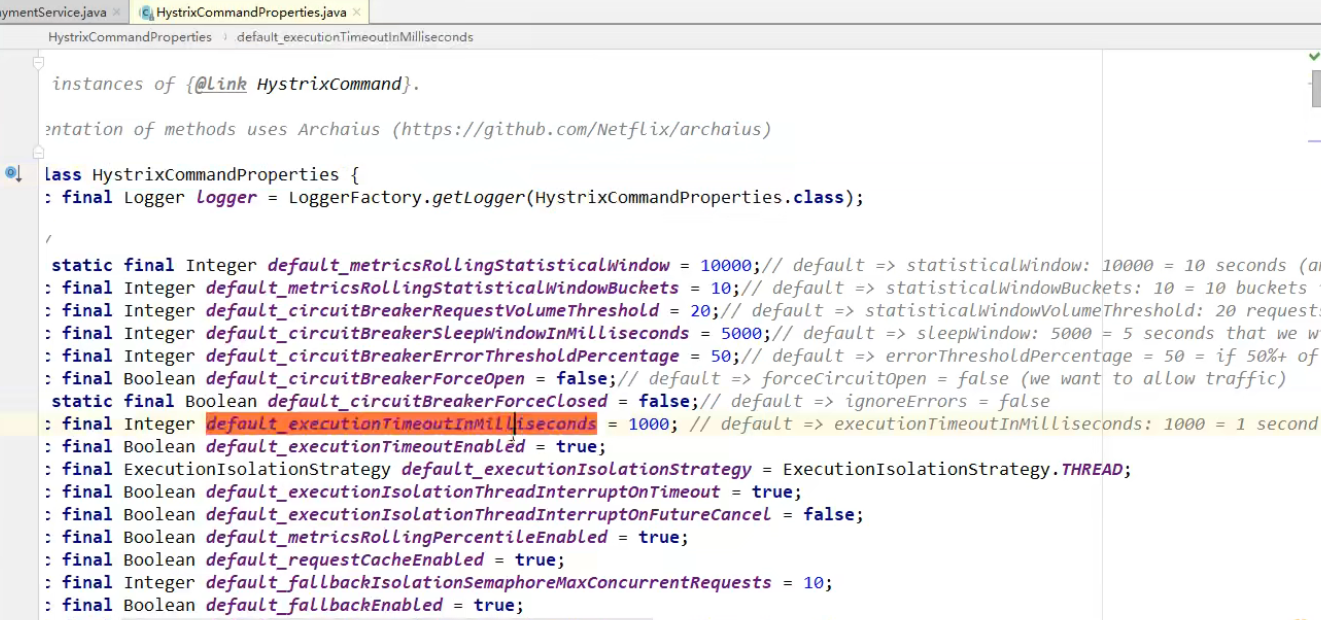
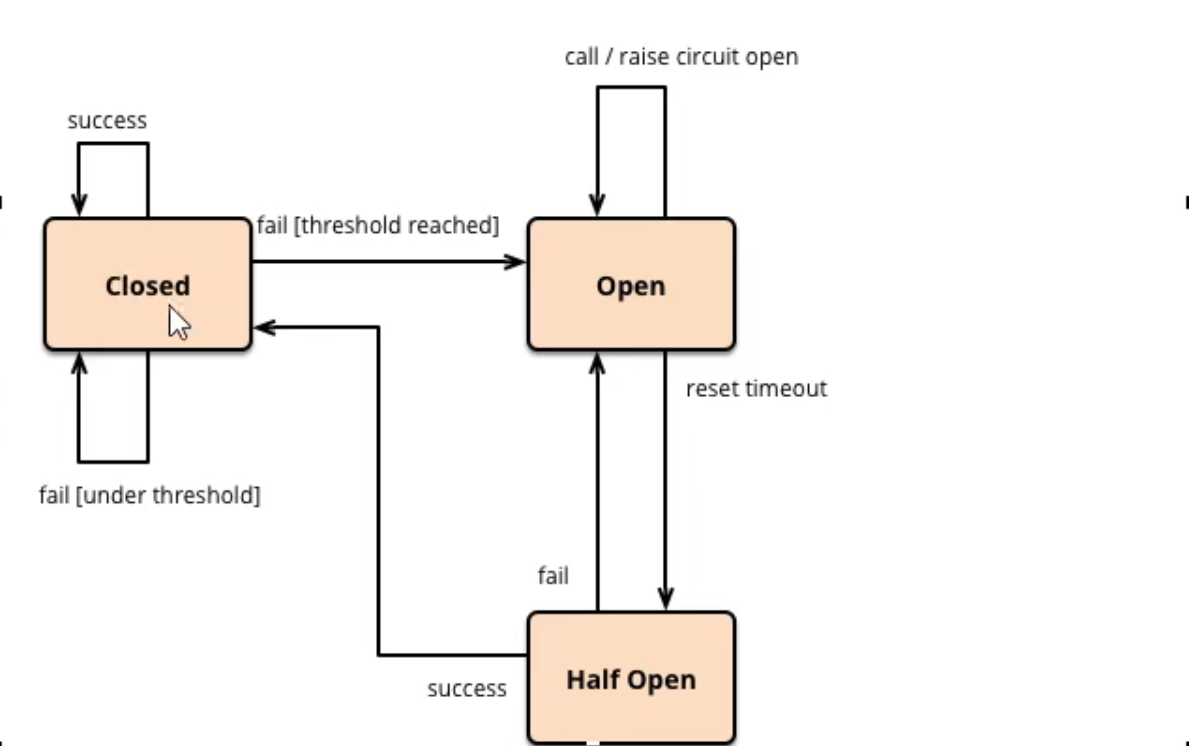
熔断器的三个状态:关闭(正常状态)、打开(断开状态)、半打开(半打开状态)
例如:
开启熔断器,在10s内10次请求里面有6次失败的话(依据配置),熔断器从【关闭】变为【打开】
过了一段时间后熔断器从【打开】变为【半打开】,尝试让请求通过,若请求没有超过配置限度熔断器则从【半打开】变为【关闭】
十二、Skywalking链路追踪
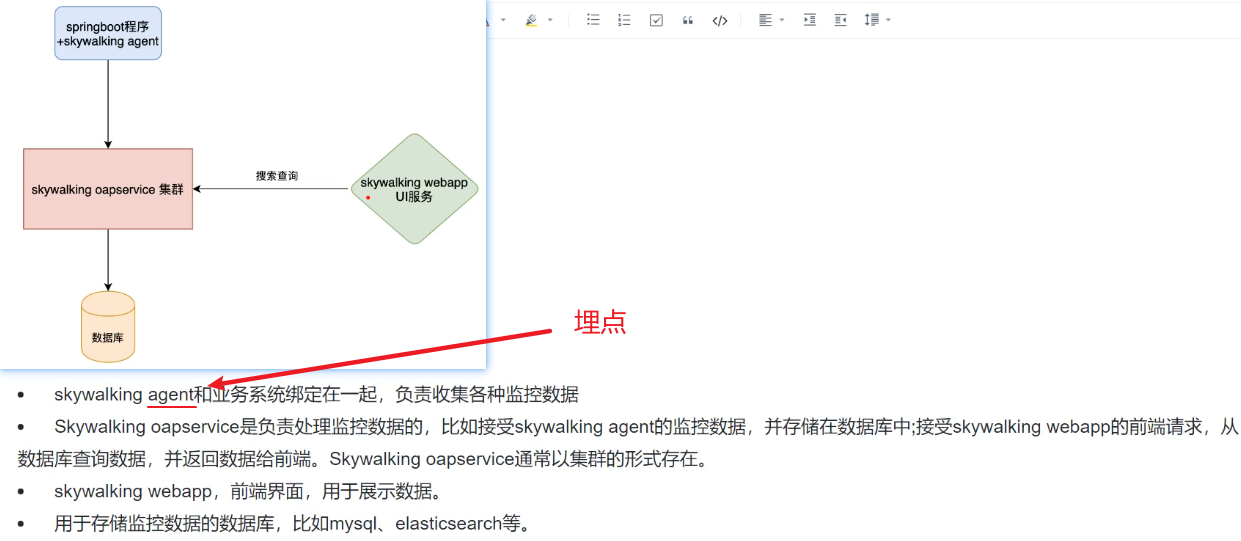
sky walking是一个国产开源框架, 2015年由吴晟开源, 2017年加入Apache孵化器。sky walking是分布式系统的应用程序性能监视工具, 专为微服务、云原 生架构和基于容器(Docker、K8s、Mesos) 架构而设计。它是一款优秀的APM(Application Performance Management) 工具, 包括了分布式追踪、性能 指标分析、应用和服务依赖分析等。 官网:http://skywalking.apache.org/ 下载:http://skywalking.apache.org/downloads/ Git hub:https://aithub.com/apache/skywalking 文档:https://skywalking.apache.org/docs/main/v8.4.0/readme 中文文档:https://skyapm.github.io/document-cn-translation-of-skywalking/ 版本:v8.3.0升级到v8.4.0
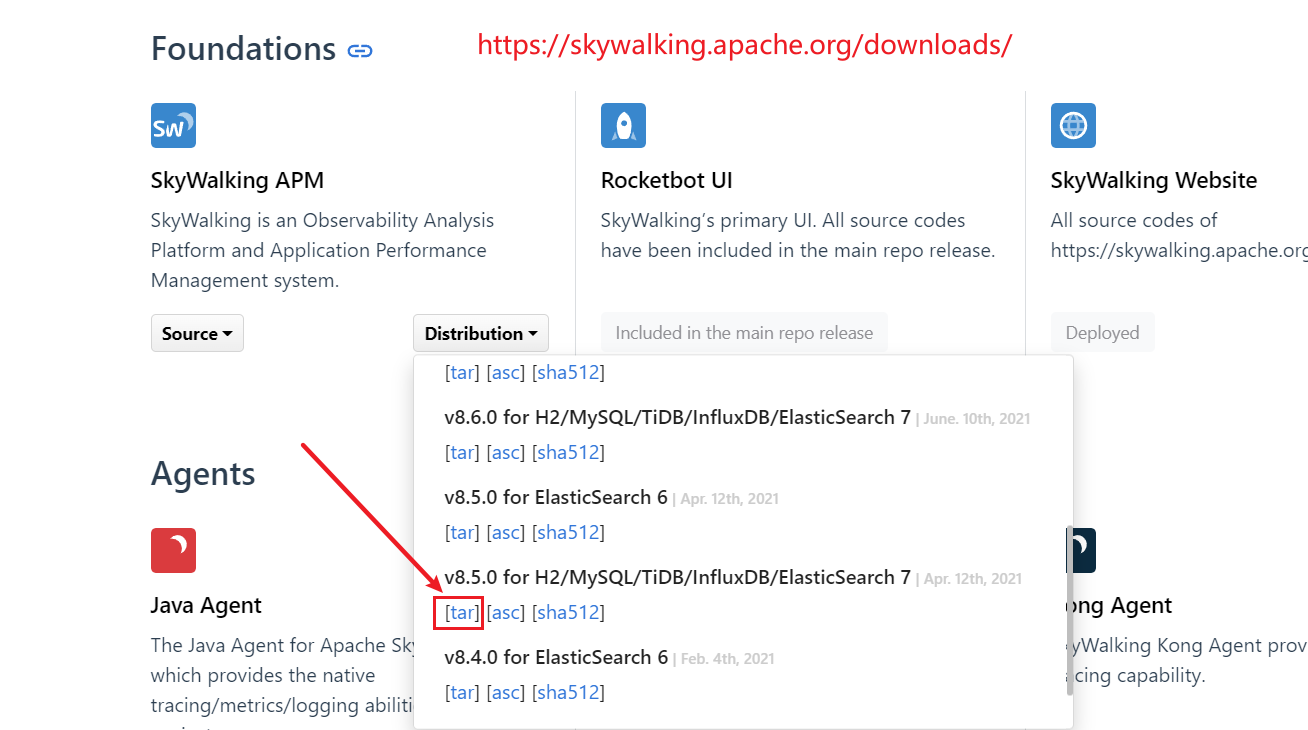
下载:http://skywalking.apache.org/downloads/
skywalking安装包
apache-skywalking-apm-es7-8.5.0.tar.gz
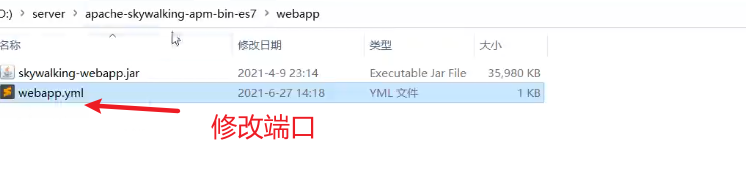
默认采用H2内存数据库
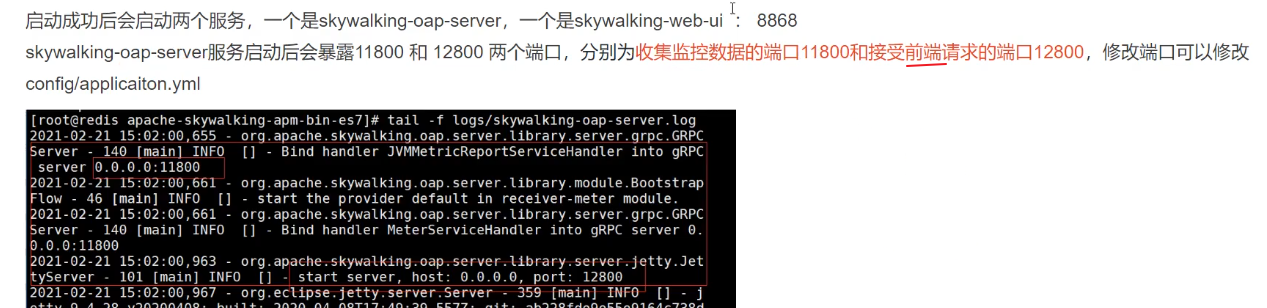
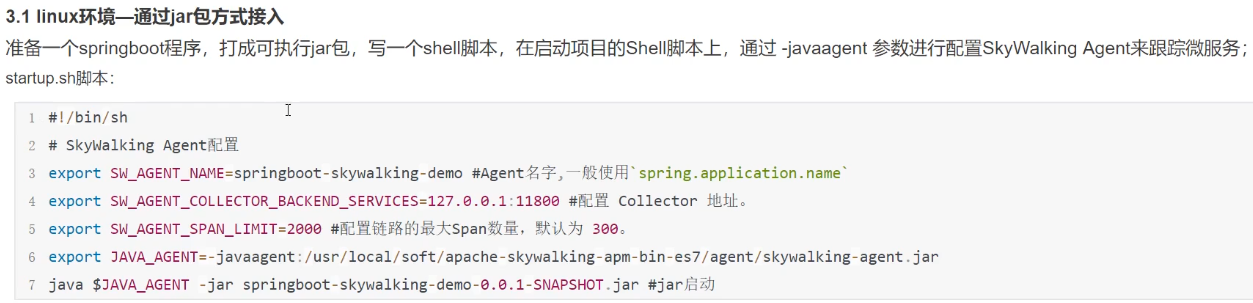
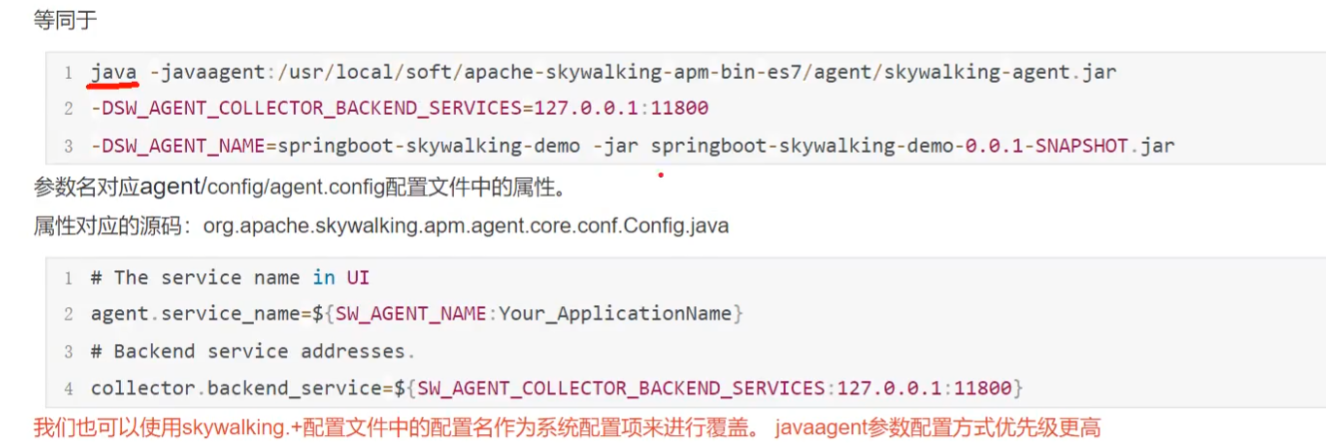
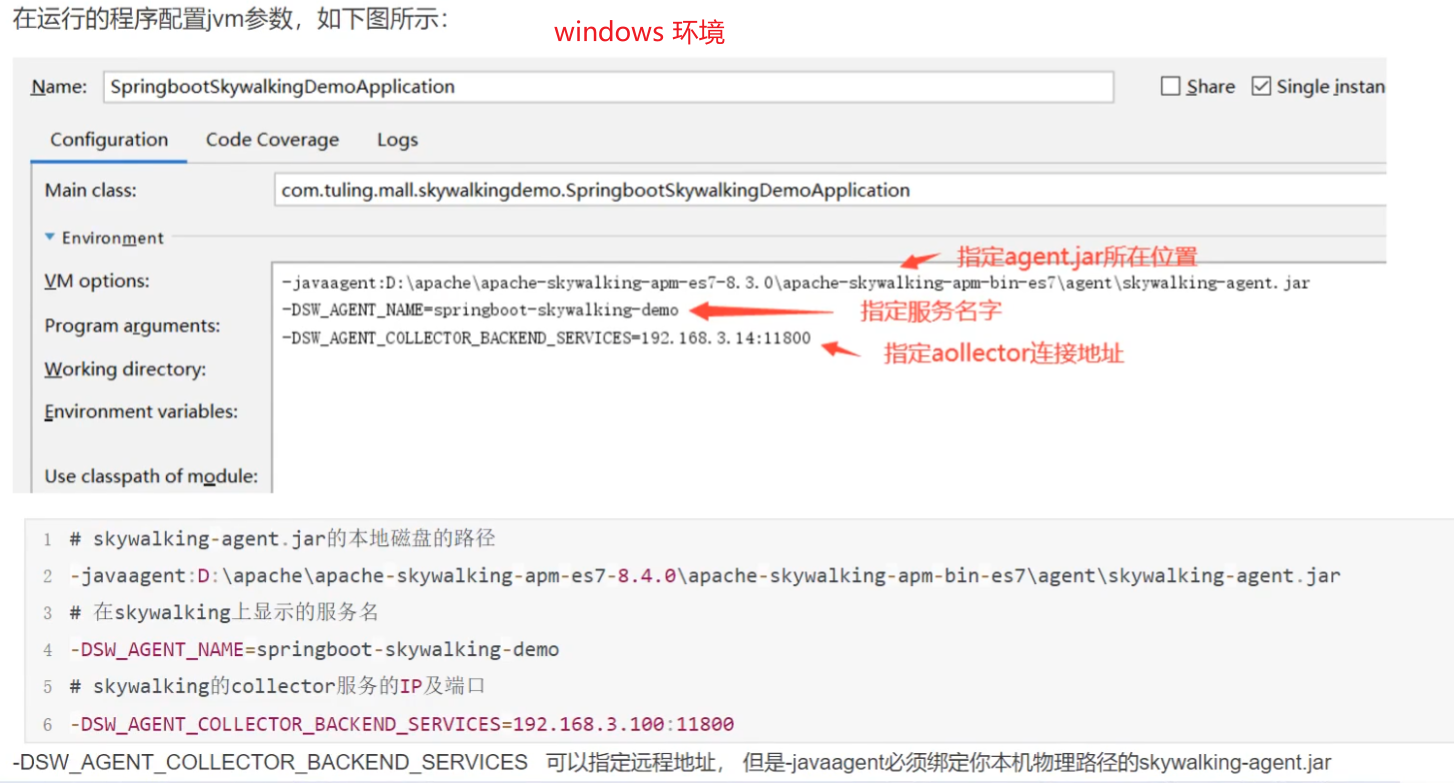
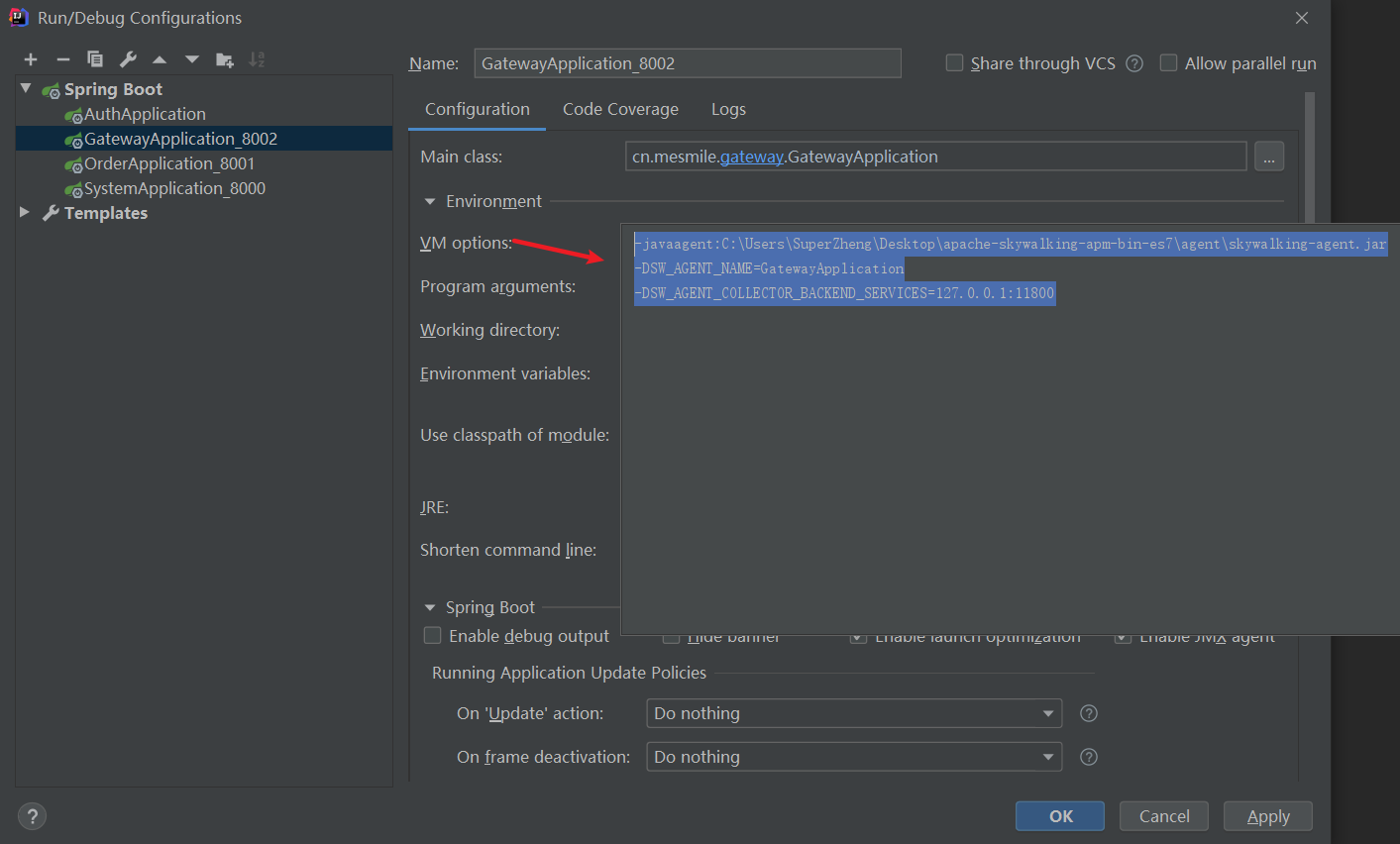
# 本地磁盘skywalking-agent.jar的本地磁盘路径
-javaagent:C:\Users\SuperZheng\Desktop\apache-skywalking-apm-bin-es7\agent\skywalking-agent.jar
# 在skywalking上显示的服务名
-DSW_AGENT_NAME=GatewayApplication
# skywalking的collector服务的IP以及端口
-DSW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800
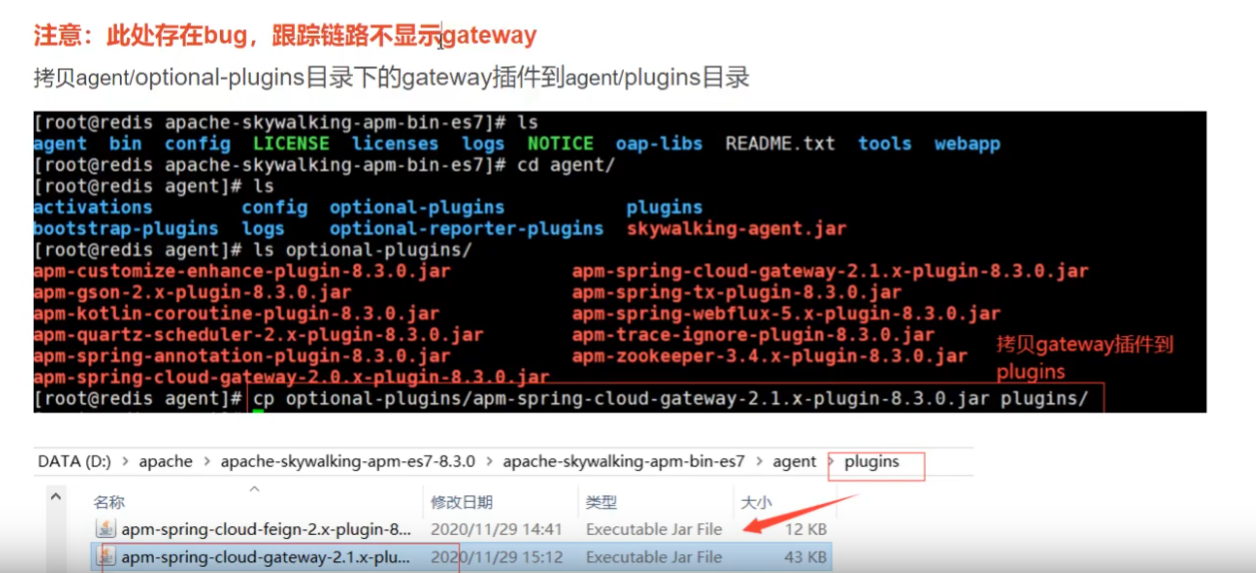
持久化
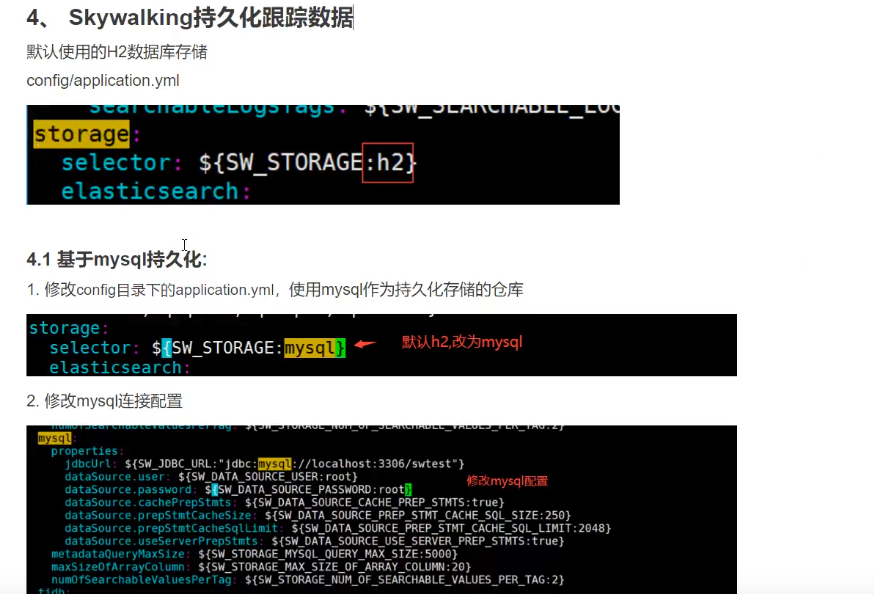
mysql驱动:
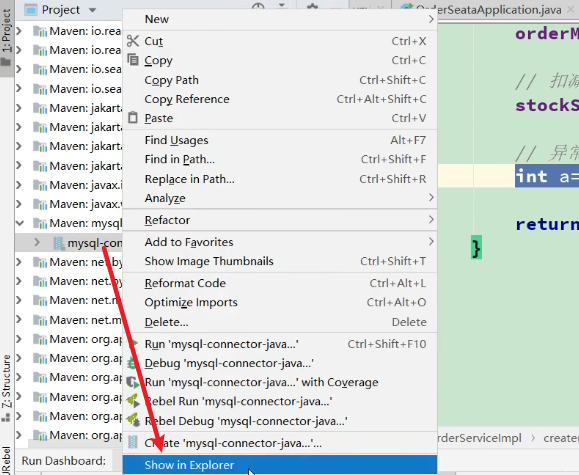
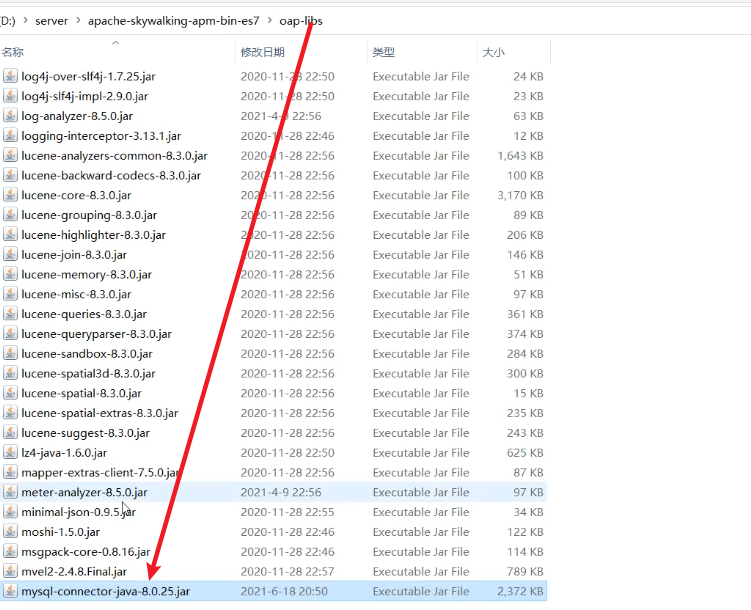
将驱动复制到安装包:
自定义业务Skywalking链路追踪
<!--Skywalking工具类, 版本号与服务端一致-->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.5.0</version>
</dependency>

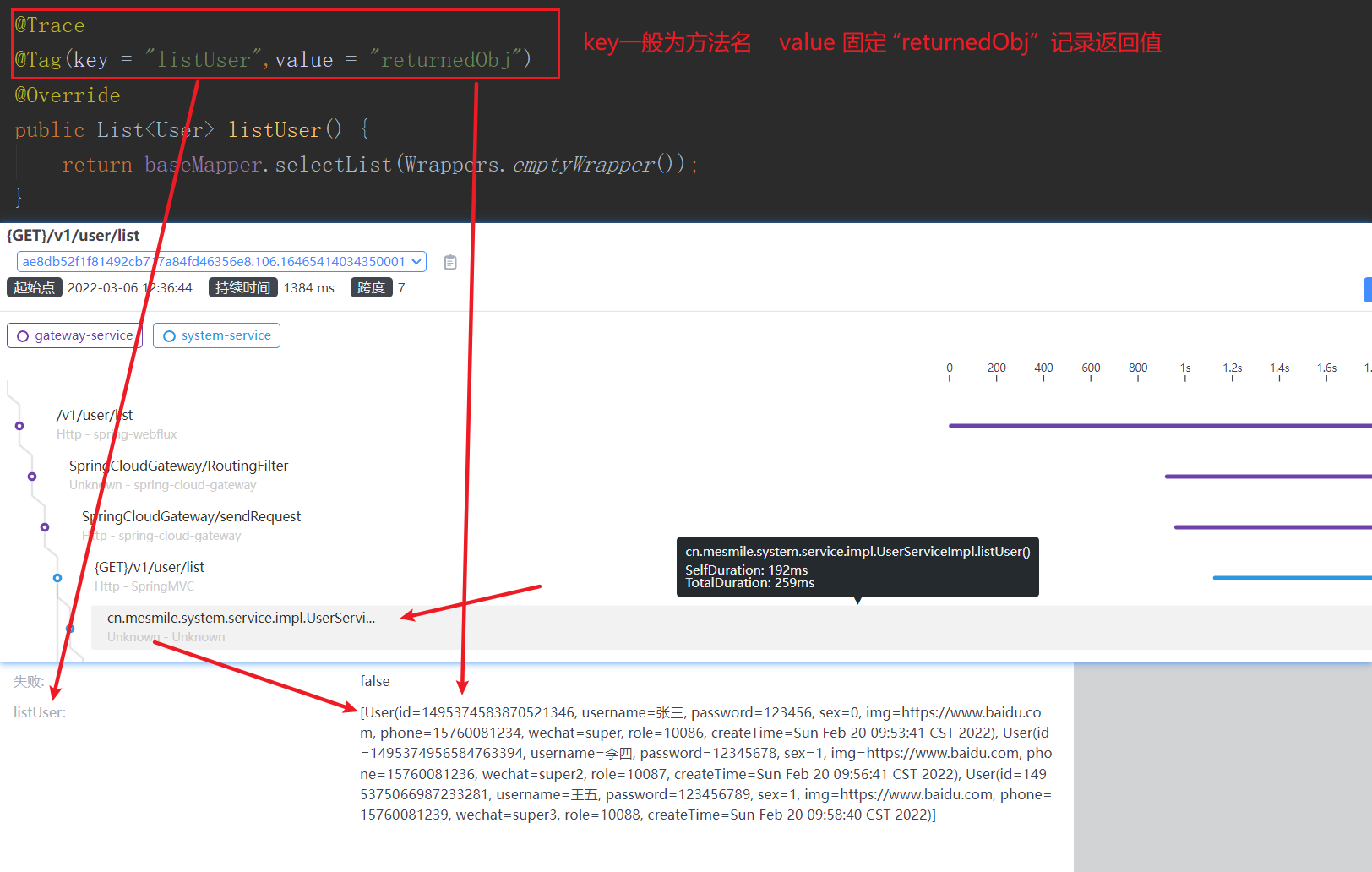
性能剖析
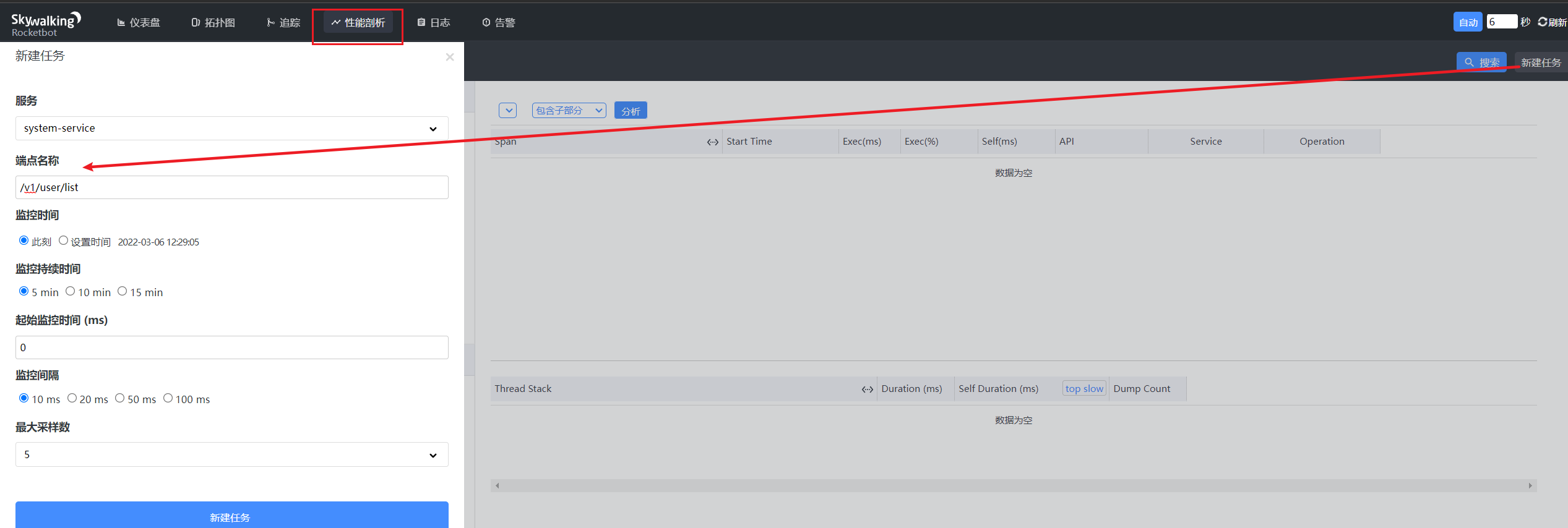
请求5次,每个10ms采样一次
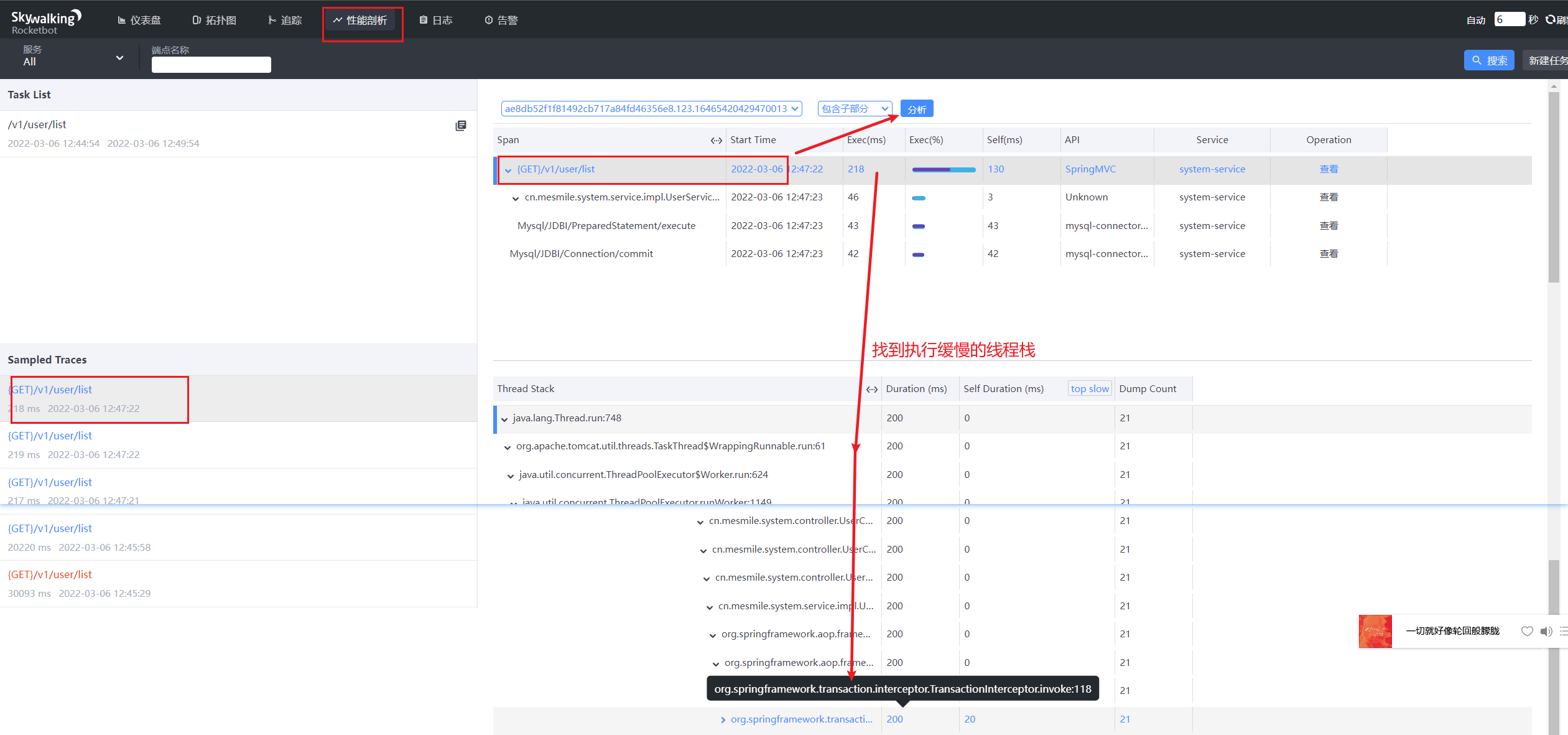
分析出了springboot第一次接口访问慢的问题(暂时无效)
SpringBoot的接口第一次访问都很慢,通过日志可以发现,dispatcherServlet不是一开始就加载的,有访问才开始加载的,即懒加载。
2019-01-25 15:23:46.264 INFO 1452 --- [nio-8080-exec-1] Initializing Spring FrameworkServlet 'dispatcherServlet'
2019-01-25 15:23:46.265 INFO 1452 --- [nio-8080-exec-1] FrameworkServlet 'dispatcherServlet': initialization started
2019-01-25 15:23:46.395 INFO 1452 --- [nio-8080-exec-1] FrameworkServlet 'dispatcherServlet': initialization completed in 130 ms这样对于我们来说是一个问题。
在SpringBoot的配置文件中添加以下配置即可:
spring:
mvc:
servlet:
# 当值为0或者大于0时,表示容器在应用启动时就加载并初始化这个servlet
load-on-startup: 1日志记录
引入插件依赖
<!-- 引入skywalking 日志依赖 -->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.5.0</version>
</dependency>
# 假如skywalking没有部署在本地,就需要配置以下内容到 agent/config/agent.config
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_SERVER_HOST:127.0.0.1}
plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_SERVER_PORT:11800}
plugin.toolkit.log.grpc.reporter.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}
plugin.toolkit.log.grpc.reporter.upstream_timeout=${SW_GRPC_LOG_GRPC_UPSTREAM_TIMEOUT:30}文档地址
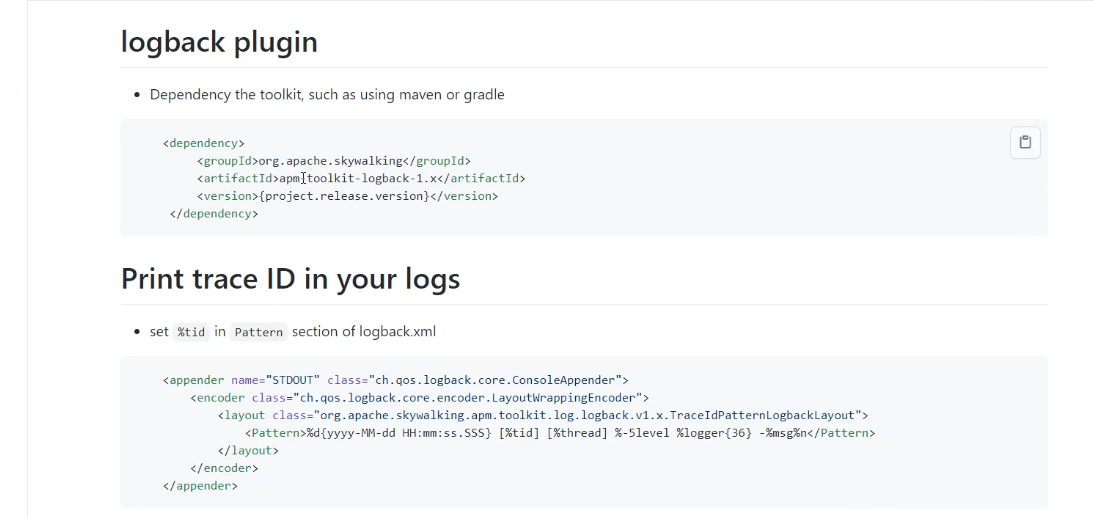
加上[%tid]这个就为traceId
logback-spring.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,比如: 如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<!--加上skywalking的追踪id-->
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<Pattern>-%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p})[%tid] %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}</Pattern>
</layout>
</encoder>
</appender>
<!-- skywalking grpc 日志收集反馈到skywalking控制台ui【日志】界面 8.4.0版本开始支持 -->
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<!--设置Appender-->
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="grpc-log"/>
</root>
</configuration>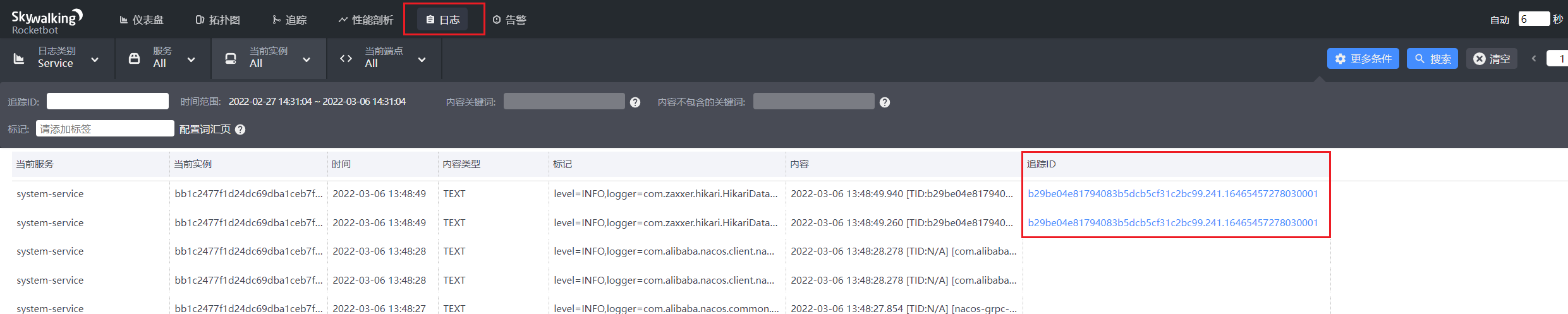
告警规则
文档地址
https://github.com/apache/skywalking/blob/v8.5.0/docs/en/setup/backend/backend-alarm.md

回调告警信息,当发送告警信息的时候,skywalking发送告警信息到其他地方
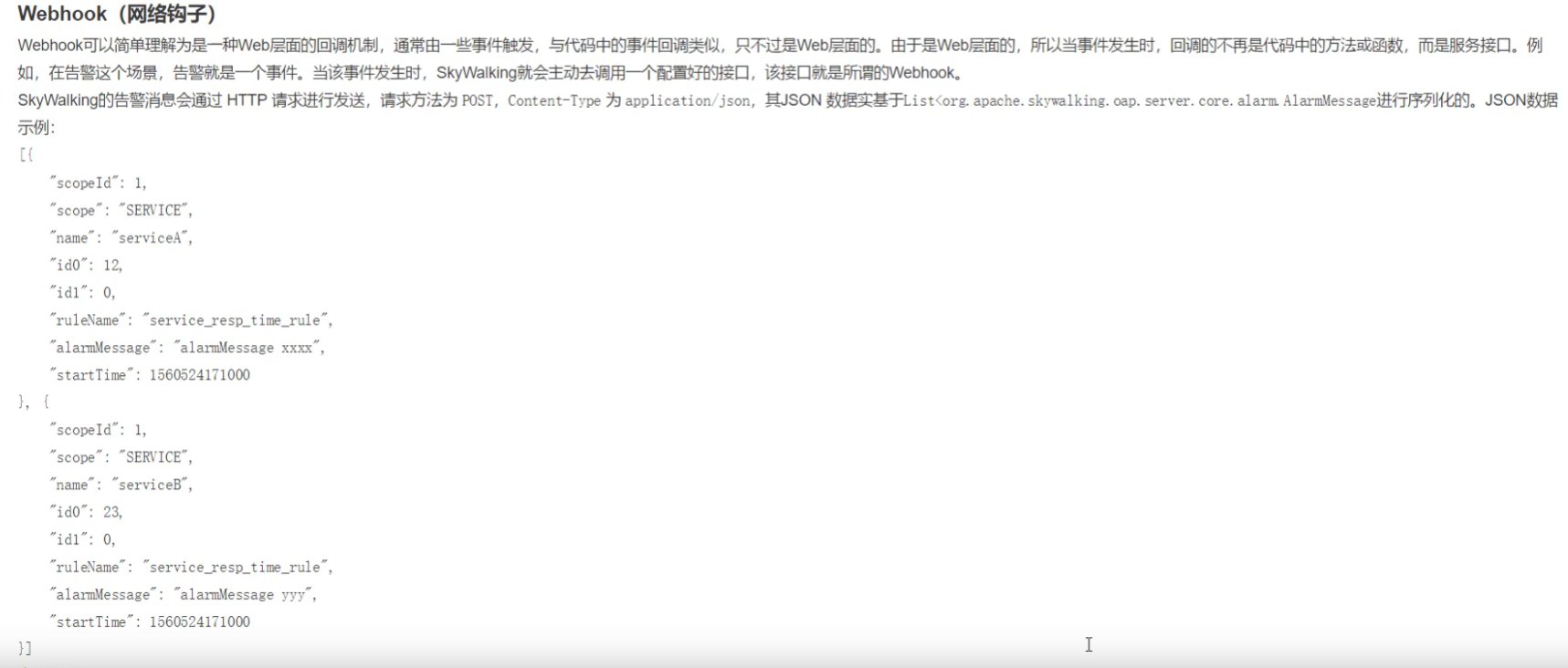

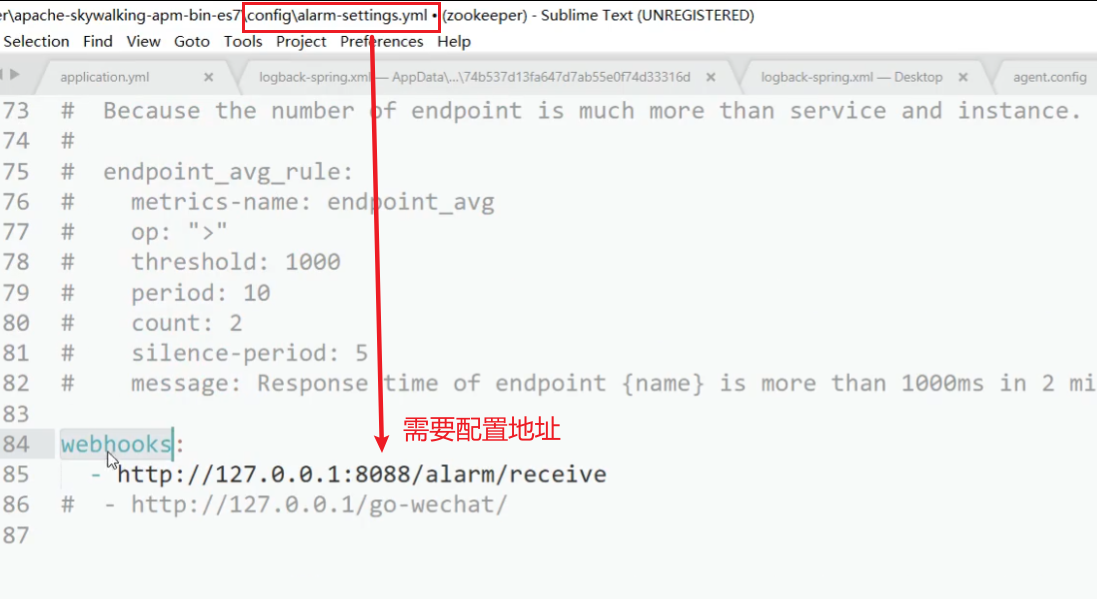
Skywalking高可用部署